Why Monero?
I wrote a lot of words about why I think monero is awesome.RandomX 2 Year Anniversary
I wrote some words about RandomX history and why PoS sucks.Writeup of the X5 "ASIC" release
In August of 2023, Bitmain released their X5 monero mining device to the world.Please run your own node
Public nodes should be considered a last resort if you can't get your own node working. The entire value of a decentralized cryptocurrency is its decentralized nature. If you are a mobile user, you can even setup your mobile wallet to connect to your home node. Please, take the time to try running your own node, or perhaps just use a remote node until your daemon is synchronized.
The only trusted node is your own
Though you probably don't care and just want a remote node. The best list is at monero.fail.
News
Site updated 2022-12-06. If you see something that needs changing, ping me on IRC or whatever
Monero CLI v0.18.3.2, GUI v0.18.3.2 is the version of Monero you should be running.
New software has a new flag, --public-node , that is good to use if you are offering public RPC service. And the new software can find its own remote nodes! Hooray, the end of these centralized node listing services is soon!
How to untar.bz2 on linux because im tired of googling it: tar -vxjf stupid.tar.bz2
Goddamn you ubuntu and your boot directory: dpkg --list | grep linux-image | awk '{ print $2 }' | sort -V | sed -n '/'`uname -r`'/q;p' | xargs sudo apt-get -y purge
REALLY make sure your open node is running with the --restricted-rpc flag. I left the explorer node open without the flag and someone started mining on it
Security note
Using a public remote node has its risks. The primary risk is that a public remote node can get your IP address. If a public remote node is malicious, the node operator now can associate a transaction with an IP address. They could also know that there is a user of monero with an ACTIVE wallet at a given IP address. They could then scan your IP address to try and identify any open ports. If they find any open ports, they can test these ports to see if they can get in to your computer. Granted, this is true of ANY IP address that can be obtained from the monero peerlists. TL;DR, run your own node. If you can't, make sure you have good firewalls, wallet passwords, and malware scanners.
Active attack vectors
The attack is pretty straightforward: when the wallet requests data from the remote node to create a transaction, the remote node sends bogus data in response. This results in an error message displayed to the user. If the user clicks through the error and retries the transaction a second time, this immediately reveals the real input to the remote node. Mitigations: If you see *ANY** error message after attempting a transaction, DISCONNECT from that remote node and DO NOT try your transaction again right away.*
High Fee Bug. Remote nodes can increase your tx fees. Double check before sending. Run the latest release of the GUI. Run your own node. Wallets still look like they are "synchronizing"
When using a remote node, your wallet still needs to download the blockchain data. This is called "refreshing your wallet" and is done whenever you create, restore, or open your wallet.
Nodes
OUT OF DATE
This section needs some massive rework, so it is here for your reference, but a lot of these nodes probably don't work anymore. Use the monero.fail or find a node offered by your favorite monero service
WARNING
HIGH FEE BUG. Remote nodes can increase your TX fees. RUN YOUR OWN NODE. CHECK YOUR FEES.
For full description of attack vector, see above. If you see *ANY* error message after attempting a transaction, DISCONNECT from that remote node and DO NOT try your transaction again right away.* Note, this has apparently been mitigated as of 2021-11-16.
Remote Node With Monero GUI
20191202 update - The below instructions can still be used, but for the most part, you should be using the boostrap mode with pruning in your Monero software.
To use remote nodes with the Monero GUI, include the node address under the Settings tab and be sure to use the proper port:
Some well maintained nodes by a community member.
Web page that keeps track of node status
opennode.xmr-tw.orgat port18089- RANDOM, UNTRUSTED. - Remote nodes volunteered by community members. Independent scanning effort from another community member. Will work with all DNS providers.node.moneroworld.comat port18089- I point this one to whatever I think is best at the time being. Currently, its a small cohort of trusted monero community members.node.xmrbackb.oneat port18081- Remote nodes maintained by Snipauwillrunanodesoon.moneroworld.comat port18089- High speed servers sponsored by community and managed by me.nodes.hashvault.proat port18081- node run by hashvault poolnode.supportxmr.comat port18081- node run by supportxmr.com pool
To check that the above addresses are working, please checkout this website. If their are no type A records in the list, then there is something wrong with the DNS server maintaining that node list, and should not be used. The provided link checks out the moneroworld.com nodes. You can manually check the other domains by entering them on the website. You can also use that link to connect to a specific node instead of a random one.
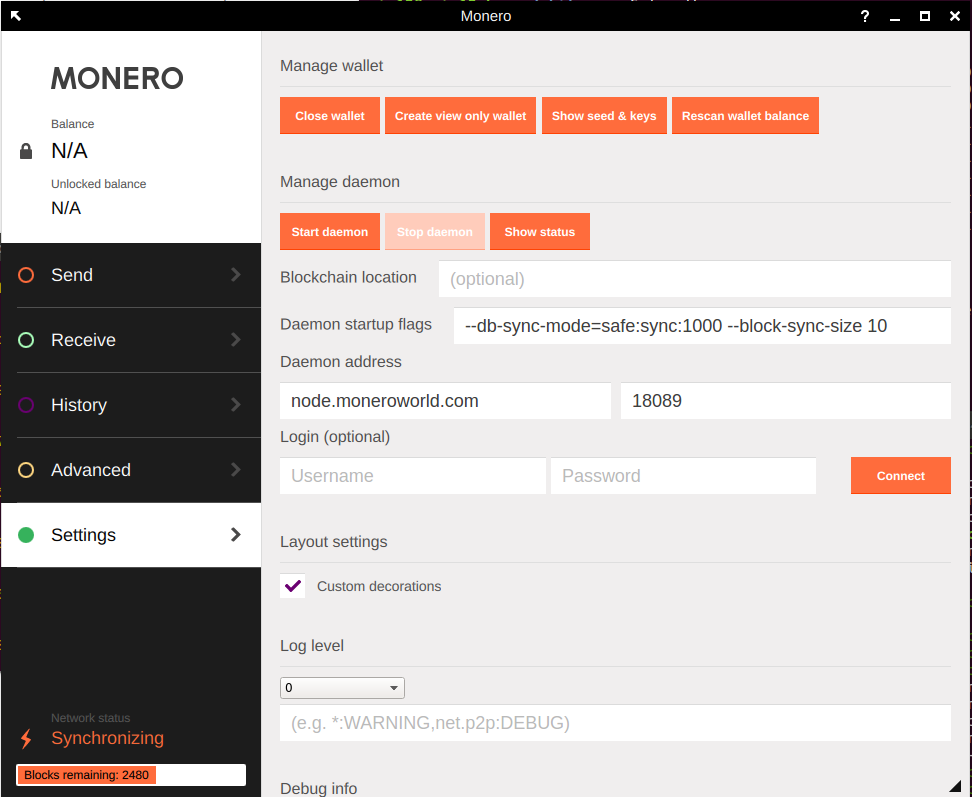
Remote Node With Monero CLI
To use remote nodes with the Monero CLI, run the following code.
Collection of random open nodes consciously volunteered by other monerians:
--daemon-address put.the.node.and:port_hereUse the nodes listed under the GUI section in the CLI
TOR Remote Nodes
Note - I don't check these, at all. No idea if they work...
monerowinfamlvkp.onionpzlnznwgrjlgjsb6.onionqjz3tnotsv7xlxj4.onionxmrag4hf5xlabmob.onion:18081xmr4xfd2o3tzazdb.onion:18081mmp26upm3gig2ltk.onion:18089xmkwypann4ly64gh.onion:180813hvpnd4xejtzcuowvru2wfjum5wjf7synigm44rrizr3k4v5vzam2bad.onion:18081
Testnet Nodes
node.xmrbackb.one:28081 should have remote access to a testnet. I think its master.
testnet.node.xmrlab.com:28081 is on testnet v6, so same as monero blockchain
testnet.node.xmrlab.com:38081 is on testnet v7, needs github master for access
i2P Mining Route
For those that want to mine via i2p, you can with MoneroWorld.com. Instructions can be found at:
http://fjetvybcoerd3dukjfxf5i7aiihlt7b2twudooakp4qcdwzwr7ia.b32.i2p/I will update this with a hostname once its registered. If you already know how to route via i2p, the mining port is:
vkohxr7ealm23uacawcjpbxi3smas2wajr5ne6sgmmw42ygvjikq.b32.i2pContribute
How To Run Your Node
You should really run your own node!
It's honestly not that hard - it can take 9 hours to synchronize if you have a SSD and a good internet connection. Also, remote nodes are NOT reliable, a lot of times they just won't connect because the software wasn't really developed for this.
Download your node software from the official website GetMonero.org and learn how to run the software here.
MoneroWorld runs a script every 5 minutes to scan the Monero network for open nodes.
How To Include Your Node On Moneroworld
THIS SECTION WILL BE REWRITTEN SOON. ALL YOU NEED TO DO NOW IS USE --public-node. There's even more fanciness with payments, so this section will get some work soon!!!
This is the stuff in the code, and a readme
I have to rewrite all this stuff after this
If you would like to offer your node up for inclusion in the Moneroworld Network of Open Nodes, you can simply add the code bellow to the launch of your daemon (and open your firewall), and the MoneroWorld script will sniff you out and add your node to the random list.
Offering your node as a remote node is above and beyond what you need to do to support the network! This is NOT necessary!!!
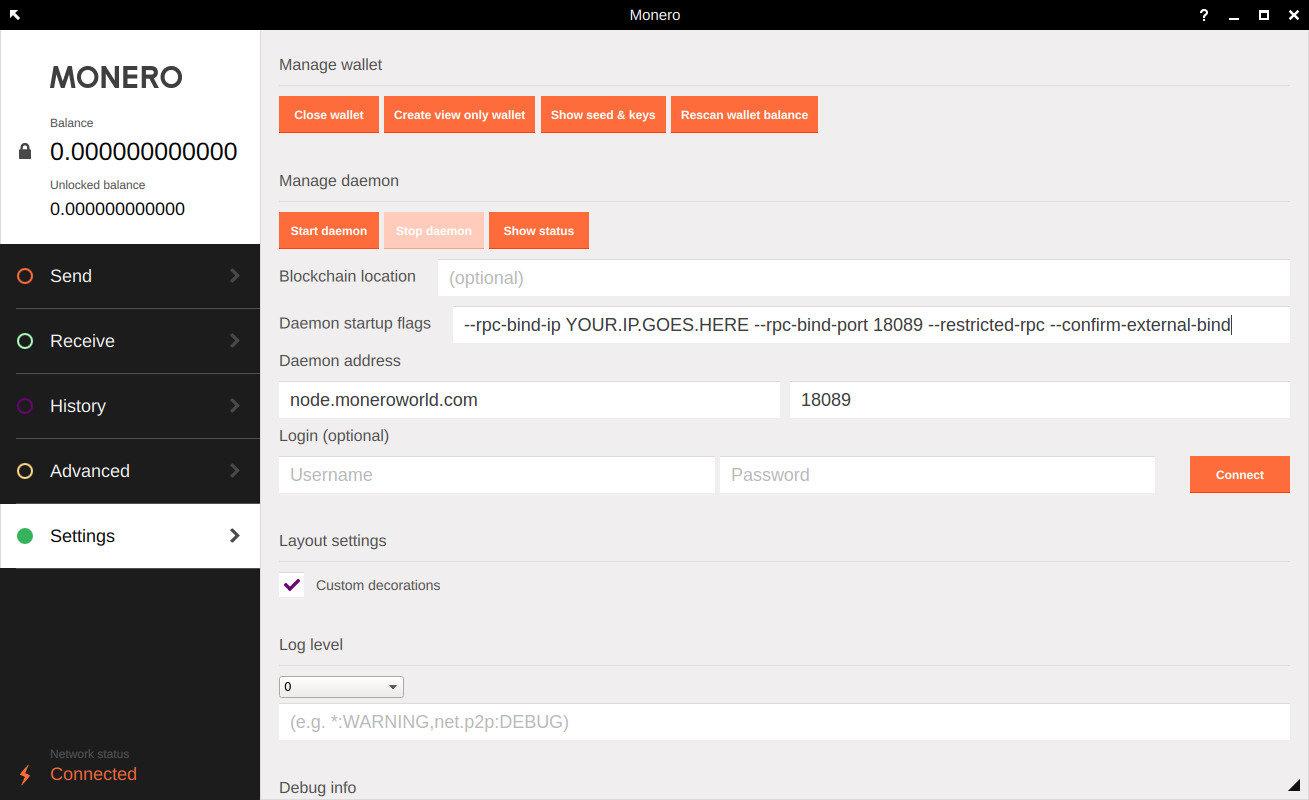
--rpc-restricted-bind-ip YOUR.IP.GOES.HERE --rpc-restricted-bind-port 18089 --rpc-bind-ip 127.0.0.1 --rpc-bind-port 18081 --confirm-external-bind --public-nodeNOTE: For YOU.IP.GOES.HERE, this is your external IP. If this is a VPS or a database hosted server, its usually the IP of the box. If this is a home computer behind a router, its the IP of the computer itself, not the wlan on the router. You'll need to do some port forwarding. This setup also configures the UNrestricted RPC to bind to home, so only local commands can access the node unrestricated.
Below is a screenshot example of using the GUI to offer a remote node. Please note that you will have to use port forwarding for 18089 to the computer running the node.... but you should already know how to open your ports if you are running a full node and have 18080 open!!! You just need to enter this information into the Daemon Startup Flags field and then start your daemon. Also note that you may have to change your Daemon Address field so your wallet can connect to your node with its external bindings.
Run the script on your own daemon!
The current version of the script is on a fork from some other user. But basically, there's no need to trust any of the remote node lists provided by MoneroWorld or the other providers. You can run this script and scan your own peer list to find open nodes. You can also run this script and provide another list service! The more the better!!!
Donate
Donation Addresses
Please consider donating to keep the services running smoothly. I run some of the nodes and some are run by other volunteers.
MoneroWorld General donation address:
44UW4sPKb4XbWHm8PXr6K8GQi7jUs9i7t2mTsjDn2zK7jYZwNERfoHaC1Yy4PYs1eTCZ9766hkB6RLUf1y95EvCQNpCZnuuMaintainer of moneroworld remote node DNS server magic
8AETR6ckJbq8i35kSP2QZY31KKSbbZ9aeXQUs17PaHhwexUiLP7ZZfnYQuds6w92KMQbCjKw6HZJDdSLC1GMeFMBBTht6qi
FAQ
What Is An Open Node?
The Monero software architecture allows for an easy way to use Monero without downloading the entire blockchain. This is called "using a remote node". Essentially, your wallet program connects to someone else's monerod (blockchain) program, a.k.a node, a.k.a. network service.
How does it work? The open node addresses actually point to many different nodes - when you request one, one in the list is selected. So if it doesn't work once, just try again.
It is negligently slower depending on the connection, prevents the need of downloading entire blockchain (which can be lengthy), and there is some information leak as detailed here. The best way to anonymously use a remote node is to use Monero with TOR or with a trustable VPN service.
That being said, no one can steal your Moneroj because you use a remote node. However, use these at your own risk.
What Is Monero?
Monero is the best cryptocurrency, ever. Seriously. 99% percent of the problems that other cryptocurrencies have, Monero has either fixed or the core team is working on fixing them soon.
Primarily, to me, the important thing is that Monero is fungible. One Monero can not be distinguished from another Monero. There is no transaction history. This is a fundamental principle of money. Anything that is inherently traceable (such as bitcoin) is not money - it is an asset. Privacy is a side effect of fungibility. Oh yeah, and the blocksize is scalable so Monero will NEVER reach a transaction limit imposed by the blocksize.
Monero is also decentralized due to the ASIC-resistant proof of work algorithm, therefore the network will never be controlled by a small number of entities.
Getting Started
Welcome! Getting started with Monero is not hard, but can take a couple of minutes. The Monero Stack Exchange is a great resource for beginners.
Get a Monero Account (Address)
There are many ways to get a Monero address. The best way is to download and run the Monero wallet. This program is available at the official Monero website. There are also excellent guides on the official website. For more information on getting started with Monero, please checkout this MoneroEric.com website or watch the video linked below.
Definitions
These are definitions that I use, and I think its in agreement with what others use.
Node: This is the standard Monero node. This means you are running the Monero daemon, the piece of software that connects to the other nodes on the network. Ideally, this software is being run on a computer where the incoming p2p port, 18080, is open, so that other nodes can connect to you.
Full node: This is somewhat semantics, but this implies that you are running a Monero node.
Mining node: You are running a full node and you are also solo mining
Open node: This implies that you have opened your RPC ports to the network, so that others can connect their wallets to it.
Remote node: This is how you would refer to an open node if you are the user of an open node. Alice runs an open node, and Bob connects to Alice's open node so he is using a remote node. Or, Bob could run his own node on a server and connect to that remote node from his home or phone.
Public remote node: This is how you would refer to an open node run by someone other than yourself that has their ports open to the public. Bob is connecting to a public remote node that he doesn't operate or know the owner of.
Monero Network and Blockchain Interface This is my preferred name for the monero node software. This definition is definitely not in agreement with what others think. But don't you think its more descriptive?
Services
Awesome Monero Accepting Services
- Cloak VPN - ENCRYPT your traffic & get an IP in the USA. No account needed!
- Monero.win - Simple monero blockchain betting.
Mining
Glory days are upon us. Randomx allows everyone with a CPU a good shot at mining something worthwhile
References
The MoneroWorld as Far as Gingeropolous Is Concerned
- supportxmr.com - quite possibly the best pool in existence!
- GetMonero.org - the webpage maintained by the core team.
- Offline Monero Address Generator - generate Monero addresses offline on your network.
- MyMonero.com - the one and only trusted web-wallet by Monero users.
- Monerobase.com - a really open Monero information repository.
- The Monero Source Code - official Monero source code on GitHub.
- MoneroBlocks.info - the best Monero block explorer in existence.
- Explore.moneroworld.com - the second best Monero block explorer in existence.
- Monerohash.com - a great US based monero pool.
- Poloniex.com - the best place to buy Monero and freak out as the price goes up, down, and all over.
- XMR.TO - the best way to spend your monero anywhere bitcoin is accepted.
- Monerodice.net - the best place to lose your monero by gambling, because proceeds go to Monero. You can also bankroll the house.
- The Monero Subreddit - the best place to see Monero stuff without crazy stupid trolling.
- "Blowing the Lid off the Cryptonote Scam, with the exception of Monero" - required reading for anyone getting into Monero.
- A nice little windows installer and monitor for the Monero Core software.
- Monero Transaction Check - nifty tool to check if transactions are successful, it was developed by Monero's Core Member Luigiiii.
- Other tools, including Ice Cold Storage account - made by Monero's Core Member Luigiiii.
- Monero Stack Exchange - the best place to find answers about common Monero questions.
- Monero.how - great website with lots of tutorials.
- localmonero.co Buy Monero with Cash! Like localbitcoins, for monero
- moneroforcash.com Buy more monero with cash, uses a different model than localmonero
- Free DNS The DNS I use. Not really monero related but they are awesome.